In general most of us believe indexes improve performance of our select queries. But as with every other thing, this too doesn't holds true universally. They only help in their specific use cases.
Indexes are sure to take a toll on your insert, update and delete queries and may even negatively impact select queries if not created properly. To judiciously create indexes we need to understand when a particular index will be of help. Below are scenarios which may help you figure out the right kind of non clustered index for your particular use case.
To begin with, let us create a test table and populate it with some data.






Indexes are sure to take a toll on your insert, update and delete queries and may even negatively impact select queries if not created properly. To judiciously create indexes we need to understand when a particular index will be of help. Below are scenarios which may help you figure out the right kind of non clustered index for your particular use case.
To begin with, let us create a test table and populate it with some data.
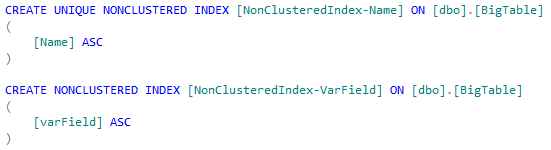
Scenario 1: One non clustered index per column
Suppose we have below query on our table. To cater this query two separate indexes one each on columns "Name" and "VarField" are required. This is so because where clause in our query has two conditions joined with OR operator.
Note: If you have 10 fields in your where clause then this doesn't means you gotta create ten indexes. You should create and test and then decide on right balance.
Create index script:
Scenario 2: Multiple key columns in single non clustered index (Composite Index)
Now suppose above query changes from OR condition to AND condition, in that case having one index comprising of both columns will be a better solution as we will get data from index in one go. If we had two different indexes one each for both fields then SQL engine would have used only one of those indexes and did a key lookup for second condition.
Create index script:
Scenario 3: Covering index
Now say we need to search on Name field and fetch value of VarField, in this case covering index comes to our rescue. Covering indexes should be created for hot columns or those fields that are accessed very frequently. If we have lot many columns and different queries fetching different set of columns then better will be to use index on where clause field only.
Create index script:
SQL Indexing is a very vast topic and I hope this will help you begin appreciating idea of making indexes judiciously and not on every other column blindly.
Happy Coding!!
